 大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」
大人問小孩: 「全世界的玩具隨便你挑? 這怎麼可能?
如果我要的玩具只有一個, 正好又被別人借走了呢?」想玩一點 AI, 又不想自己直接面對 封閉的 nVidia 顯卡驅動程式 嗎? 如果你的訓練資料沒有隱私或機密的問題, 那就上雲端租用 GPU 吧。 我採用的是 floydhub。 根據 這一篇比較文, floydhub 的效能比 AWS 跟 paperspace 略遜一籌; 不過他們以軟體環境取勝: 有許多現成的深度學習 docker 環境 可選。 而且當初我起步機器學習, 就是靠他們做的一些 docker images, 所以就寫介紹文來回饋囉。
你需要先註冊一個帳號, 每個月可免費使用 CPU 20 小時。 然後根據
官網文件, 以普通人的身份下 pip install -U floyd-cli
在你的電腦上安裝 floyd 指令。 (
會安裝在 ~/.local/bin 裡面)
再來下 floyd login
這會在瀏覽器開啟一個登入分頁。
登入後, 瀏覽器上會出現一個 「Copy and paste the token in your terminal」
的訊息。 點 「Copy」、 回終端機按 Enter、 貼上、 按 Enter。
輸入帳密, 然後就可以從終端機操作你的 floydhub 帳號。
一個帳號裡可以有好幾個 projects, 例如可以分別為
Caffe 遷移學習、
街道圖片語義分割、
人臉辨識 各建一個 project。
所謂建立一個 project, 就是在你的電腦裡建一個目錄、
用 floyd init 自取名稱 進行 「初始化」 手續、 把程式碼丟進去。
這個目錄裡最好不要有太多、 太大的檔案,
因為每次執行時, 整個目錄當時的內容會被搬到 floydhub
上的一個 docker 去執行。 以下我們以遷移學習 github repo
當中的 「辨識」 程式碼 cnclassify 來做測試:
mkdir transfer ; cd transfer; floyd init transfer wget https://raw.githubusercontent.com/ckhung/transfer-learning/master/cnclassify.py wget https://raw.githubusercontent.com/ckhung/transfer-learning/master/synset_words.txt
大部分時候你不會在 floydhub 上開啟一個 shell。 它的運作方式比較像是網路印表機: 你在某個 project 的目錄底下啟動一個 job , 然後就跟大家一起排隊, 等待別人、 等待你自己的 job 做完。
 但貴哥是命令列控, 所以找到
開啟 shell 的方法:
但貴哥是命令列控, 所以找到
開啟 shell 的方法: floyd run --mode jupyter
這會在 chromium 裡面開一個分頁, 連到 floydhub 的 jupyter notebook。
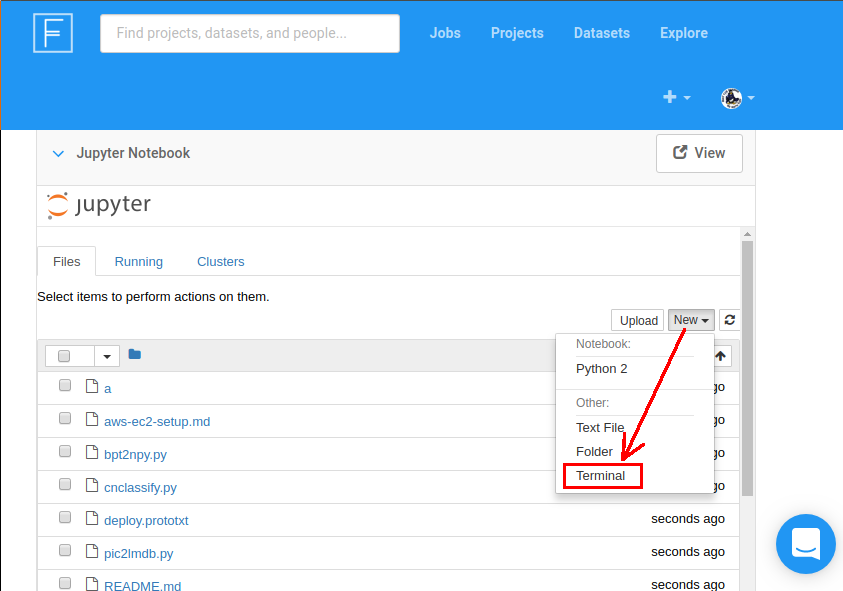
在一個很不起眼的 「new」 按鈕底下, 選 terminal,
又會開另一個 chromium 分頁, 然後就有 shell 可用了!
從這裡可以探索未來你的 jobs 執行的環境。
兩點提醒: (1) 如果你不去動它, 一兩分鐘內它就會當掉不能用。
再開另一個 terminal 用 ps x 查看, 會看到先前當掉那個 bash 還在。
不過有沒有 kill 先前的 bash 都沒差, 因為... (2) 請切換到
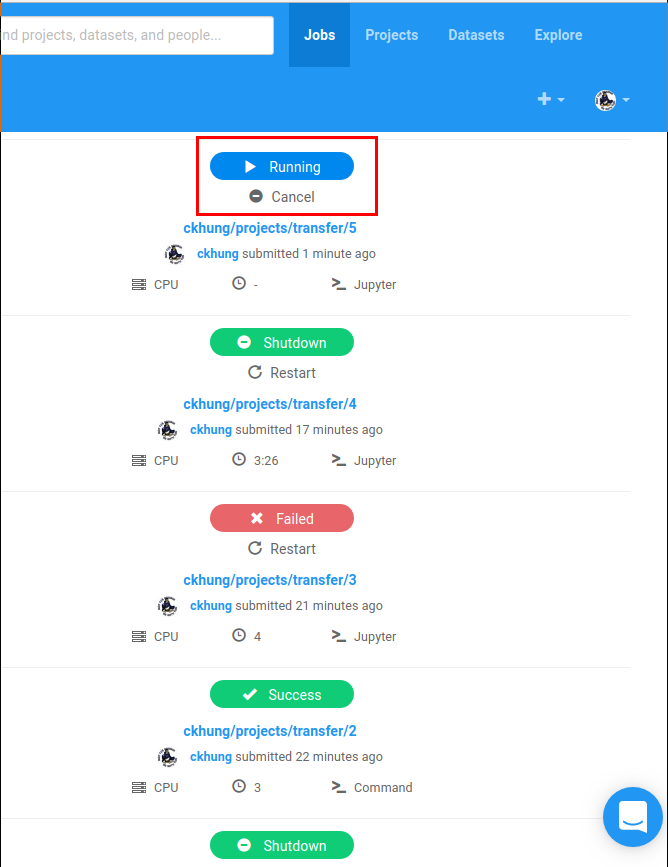
jobs 分頁, 會看到 最上面有一個 「Running」,
代表你一直在燒時間! 用完後請記得一定要把它停掉!
紅色的 Failed 或綠色的 Success、 Shutdown 都沒關係;
但如果放著藍色的 Running 不管, 就直接關瀏覽器分頁,
那麼你 (可能是花錢買來) 的寶貴時間就會一直燒掉。
回到我們的 transfer project。 本文只做辨識, 不做訓練。 假設你已在自己的電腦上用 docker 玩過 影像辨識 caffe 初體驗。 即使只是要辨識, 至少也還需要模型、 權重、 圖片等等檔案; 單單是剛剛 wget 的兩個檔怎麼夠呢? 正因為權重跟圖片檔資料量太大, 不適宜每次上傳, 所以要分開處理。 如何上傳資料集 (dataset)? 官方文件 解釋得很清楚。 為了加快腳步, 這裡我們就省略上傳資料集的步驟, 直接使用兩個全世界都看得到、 現成公開的 data sets。 (所以說如果你的訓練資料有隱私或機密的問題, 就不應該用雲端服務。) 一個是從 Explore => Trending Datasets 找到的 floydhub/datasets/vgg-ilsvrc-16-layers, 另一個是我胡亂蒐集、 上傳的測試圖片集 ckhung/datasets/images。
現在可以啟動一個 job, 把它丟到 floydhub 去執行:
floyd run --env caffe:py2
--data ckhung/datasets/images:/images
--data floydhub/datasets/vgg-ilsvrc-16-layers:/vgg
'python cnclassify.py --labels ./synset_words.txt
--model /vgg/VGG_ILSVRC_16_layers_deploy.prototxt
--weights /vgg/VGG_ILSVRC_16_layers.caffemodel
/images/6-sleeping-puppies.jpg > out.txt'
詳細解說:
- --env 指定要從 眾多深度學習 docker 環境 當中挑哪一個
- --data 的語法類似 docker 指定與 host 分享目錄的 -v 選項, 只不過現在冒號前面改成資料集名稱而非 host 目錄。 冒號後面一樣是 docker 內的對應路徑。
- 最後一長串單引號內的, 就是在 docker 裡面執行的指令。
你的程式碼會被上傳到 /code 這同時也是你的程式的工作目錄 (pwd);
運算結果一定要存到
/output目前目錄底下, 等一下才方便直接從網頁介面查看。
他們的 CPU 有點慢, 可能要等個 20 秒左右才看得到結果。
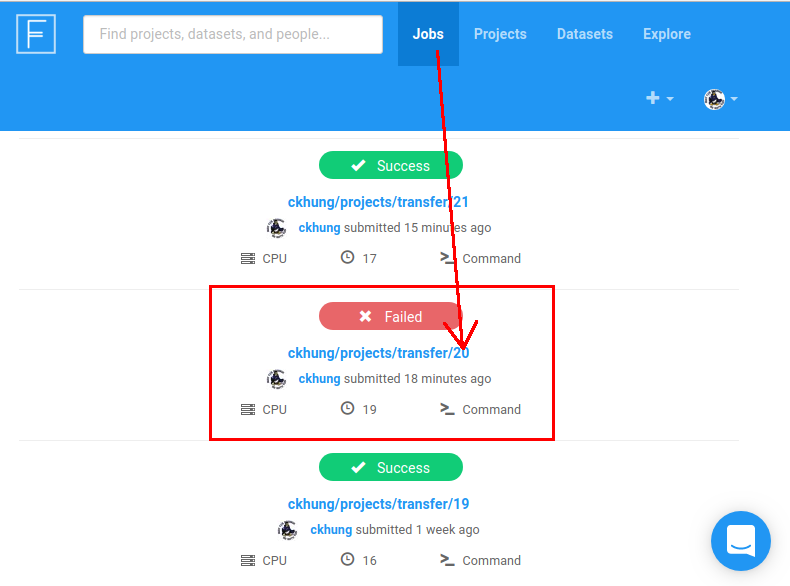
如果結果是 「Failed」, 就從瀏覽器裡點那個失敗的 job 的代號。
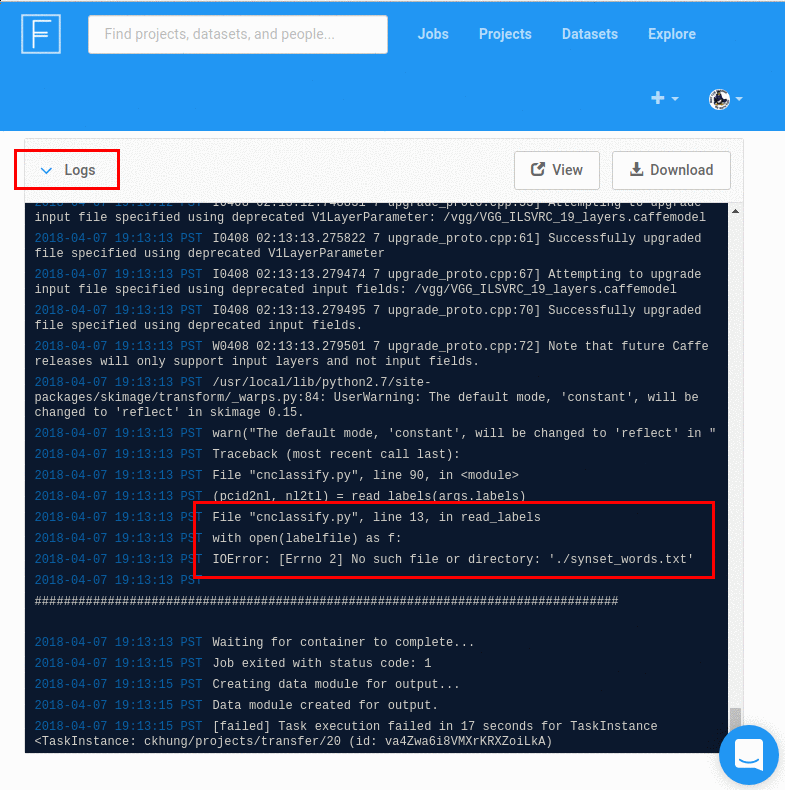
進去以後往下拉, 最下面會有 「Logs」。
在這裡找你的 python 程式碼的錯誤訊息。
例如附圖顯示我第一次忘了附 synset_words.txt 這個資料檔。
或是如果偏好用命令列查看的話, 照著當初命令列的提示打
floyd logs ... 也可以看見 log。
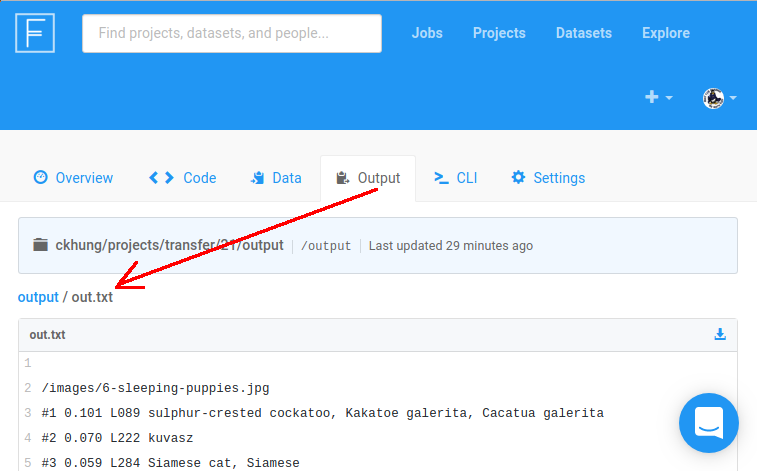
如果結果是 「Success」, 一樣點那個成功的 job 的代號、
切換到 Output Files 分頁,
看到除了先前上傳的幾個檔案之外, 會多出一個 out.txt 。
點進去檢查結果。
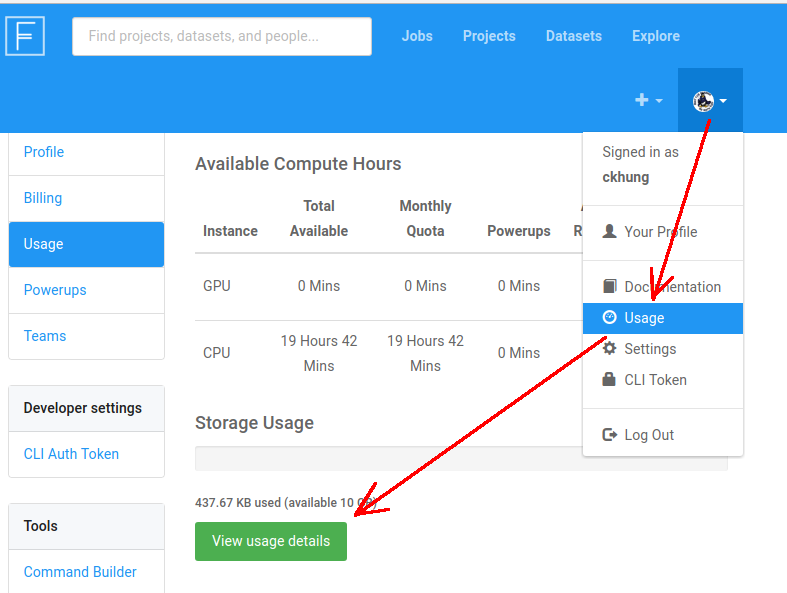
跑過幾個 jobs 之後, 可以從右上角你的頭像那邊進去,
點 usage 查看還剩多少 CPU/GPU 時間可用、
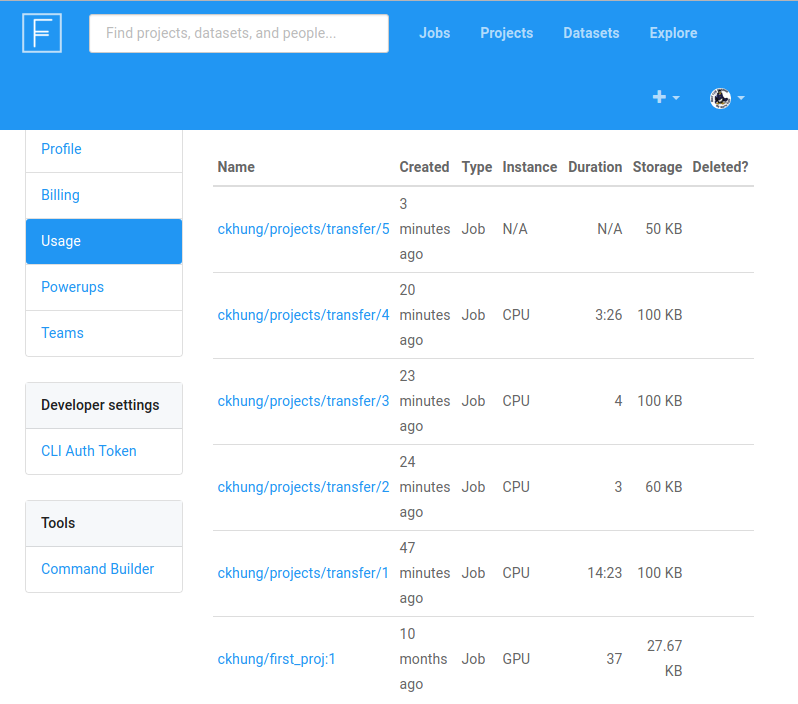
再點 usage details 查看歷來所有 jobs 各花了多少時間及儲存空間。
以上都是免費試用。 接下來從右上角頭像那邊進入 Usage、 點 GPU 那一列右邊的 get more hours、 選 standard GPU 10 小時、 輸入信用卡資訊, 點數給它買下去。
然後就可以試用 gpu。 呵呵這是燒錢測試,
可以不必跟著做, 直接看這一段最後面的小結論就好。
執行: floyd run --gpu
--env caffe:py2 --data ckhung/datasets/images:/images
--data floydhub/datasets/vgg-ilsvrc-16-layers:/vgg
'python cnclassify.py --gpu 0
--labels ./synset_words.txt --model /vgg/VGG_ILSVRC_16_layers_deploy.prototxt
--weights /vgg/VGG_ILSVRC_16_layers.caffemodel
/images/horses.jpg > out.txt'
第一個 --gpu 是告訴 floydhub 網站你要用較貴的 GPU 服務;
第二個 (單引號內的) --gpu 0 則是告訴 docker 你的程式要用第 0 號 GPU。
如果 log 檔出現 「Cannot use GPU in CPU-only Caffe: check mode」
那表示你忘了在 floyd run 後面加上 --gpu
所以它開給你的是 CPU-only 環境;
如果命令列出現 「You do not have enough credits to run this job.
Please buy a powerup to continue running jobs」
那表示你的指令可能下對了, 但是沒付 $$ :-)
結果先前 18 秒左右的 job 現在花了將近一分半才做完,
而且從 job 的統計數據上可以看見
GPU Utilization 是 0%。
但是從 Usage => View Usage Details 資訊當中看到
這次是依照 GPU 計費沒錯。
如果你用 floyd run --gpu --mode jupyter
--env caffe:py2 ... 再叫出 terminal,
可以在瀏覽器內的終端機裡下
nvidia-smi , 會看到確實有 GPU 可用。
再從這裡下 cd /code ; python cnclassify.py --gpu 0 ...
會發現一下子就做完了。 應該是因為單一的 forward pass
對 GPU 來說根本不夠塞牙縫, 完全無感;
反而時間都花在啟動 GPU docker instance, 而當時正好很多人在搶 GPU。
改成一口氣辨識十來張圖片, 就可以明顯看出 GPU 的速度比 CPU 快很多了。
結論: 小量的工作不要啟動 GPU instance。
(記得停掉那個 jupyter 的 job -- 它還在燒 GPU 點數!)
以下是更多參考閱讀:
- floydhub 入門教學 這是本文的主要參考來源。
- 如果 設定上傳/執行程式碼時,忽略(不要上傳)某些(大)檔案, 就可以讓 floydhub 的 project 跟 github 的 repo 共用目一個錄。
- 有時可能需要對一個很大的資料集進行 小規模的部分更新。
- 找到網路上公開的資料集, 不想下載回自己的電腦再上傳到 floydhub? 開一個 shell 用 wget 抓、 再把 /output 變成 floydhub 資料集。
- 預設的環境不夠用, 可以 安裝額外套件。 「只欠 python 套件」 的情況最簡單; 不論是什麼額外套件, 都是每個 job 執行時重裝一次。
- 真正實作高手寫的長文 Lessons Learned Reproducing a Deep Reinforcement Learning Paper 最後面分析 floydhub 的優缺點。
Floydhub 服務、 docker 技術、 caffe 與 tensorflow 等等開發環境, 當然還有 github 上面許多學者釋出的原始碼及訓練好的現成權重矩陣, 這些好物把人工智慧的門檻拉到非常低, 而且 除了 nVidia driver, 從上到下整個 stack 都是自由軟體。 如果你們公司需要能夠快速導入 AI 技術的人才, 或許從自由軟體社群裡找到的 AI 玩家可能還比某些很少用 linux、 專注於用昂貴的專屬軟體量產論文的學院派 AI 學者更能夠 整理資料 及解決許多繁瑣的系統問題、 讓你在資源不足的情況下也能起步測試呢! 例如下學期不論系上電腦教室有沒有 GPU 可用, 我都敢開 「人工智慧實作」 的課 :-) 現在你只欠一位擅長搜尋網路資源、 不求甚解工程師 等級的黑手講師幫你們起個頭。 快辦研習邀請我去講課吧 :-)


沒有留言:
張貼留言
因為垃圾留言太多,現在改為審核後才發佈,請耐心等候一兩天。